Code:
import urllib2
import re
from BeautifulSoup import BeautifulSoup
soup = BeautifulSoup
gt = raw_input("Tell me your gamertag: ").replace(" ","%20")
link = 'http://www.bungie.net/Stats/Reach/Screenshots.aspx?player='+gt
print "Loading page...\n"
page = urllib2.urlopen(link).read()
soup = BeautifulSoup(page)
files = soup.findAll(attrs={'class' : 'info'})
if len(files) > 0:
for w in files:
title = str(w.find(id=re.compile("title")).contents[0])
highres = w.find(id=re.compile("hiresLink"))['href']
print title
print "http://www.bungie.net"+highres
pic = urllib2.urlopen("http://www.bungie.net"+highres)
file = open(title+".jpg","wb")
file.write(pic.read())
file.close()
raw_input("Press Enter to exit")
if len(files) == 0:
print "no screenshots found"
raw_input("Press Enter to exit")






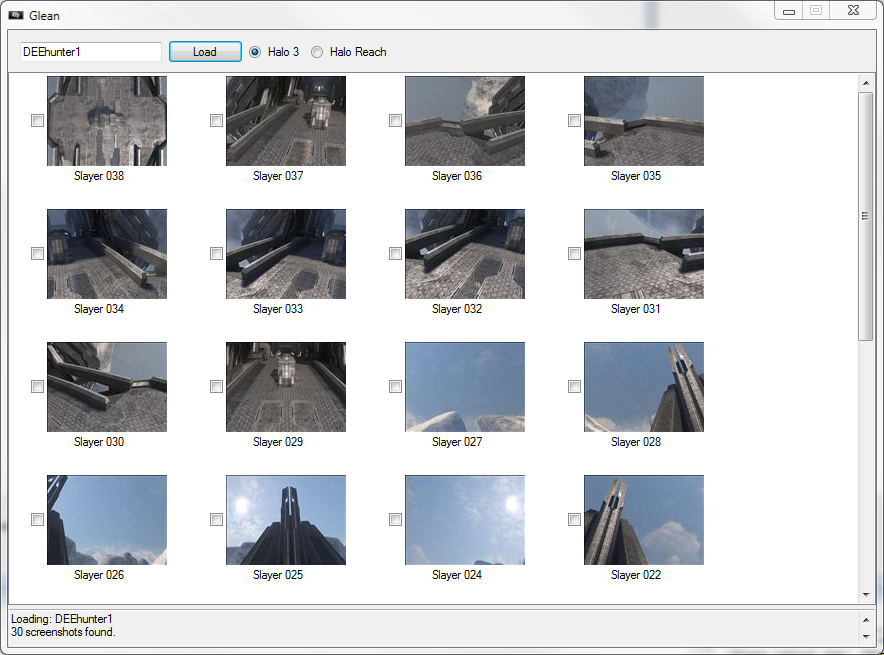

Bookmarks